Why in news?
Researchers have warned that generative AI systems may suffer from “model collapse” when they are repeatedly trained on their own outputs instead of fresh human‑generated data. A new study by King’s College London, Simon Fraser University and the University of Oxford shows that inserting even one genuine data point into training can delay or prevent this degradation.
Background
Generative AI models—such as large language models or image generators—learn patterns from huge datasets and then create new text, images or music. If future models are trained mostly on content produced by older models, errors and biases can accumulate. Over successive generations, the models may converge on bland or incoherent outputs, losing their diversity and factual grounding; this phenomenon is called model collapse.
The problem is related to an older concept known as “garbage in, garbage out”: the quality of an AI’s outputs depends on the quality of its training data. When synthetic data dominates, rare features and long‑tail information disappear, causing the model to forget how to handle unusual cases. The effect has parallels with catastrophic forgetting in neural networks.
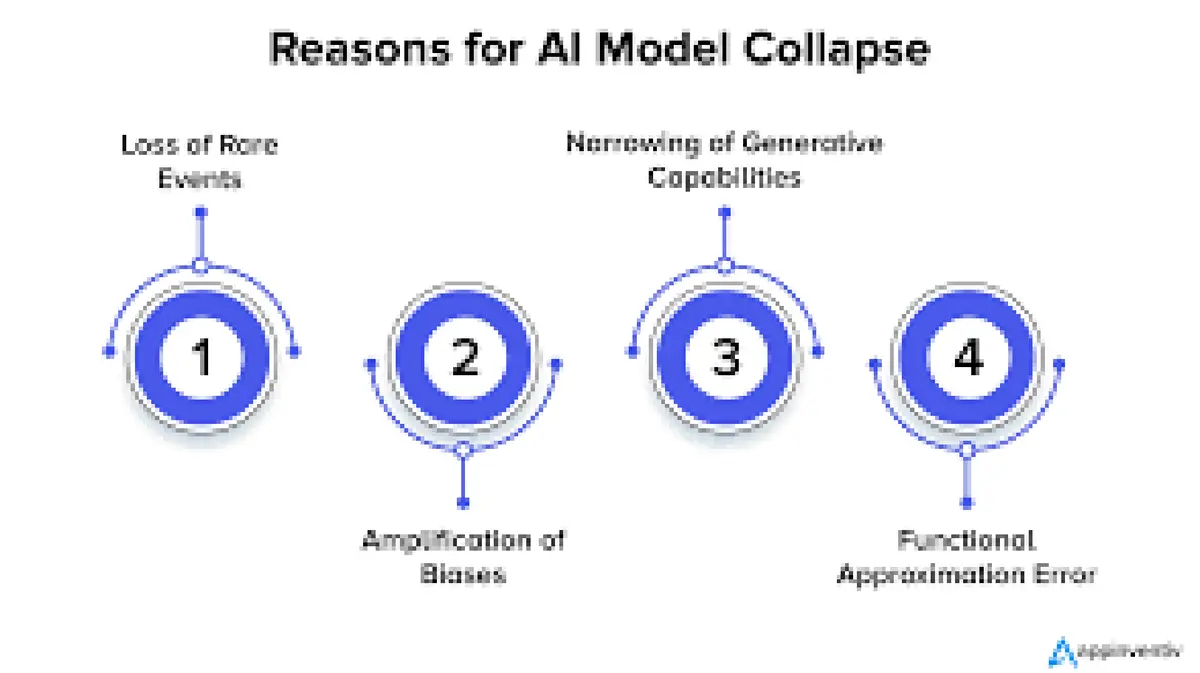
Findings of recent research
- The study used mathematical models called exponential families to simulate repeated learning on synthetic data. It found that the distribution of data narrows over time, causing models to produce a shrinking variety of outputs.
- Inserting just one real, out‑of‑distribution data point or encoding a prior belief into the training process interrupts this narrowing and keeps the model’s output closer to reality.
- The results apply across several types of generative models, suggesting a simple guideline: always blend real human data into training sets and track the provenance of synthetic content.
Consequences and mitigation
- Consequences: Model collapse can lead to unreliable recommendations, poor decision‑making, and the erosion of knowledge in automated systems. It undermines user trust and can harm industries that rely on generative AI for content creation, design or diagnostics.
- Mitigation strategies: Researchers recommend documenting data sources, preserving access to original datasets and using quality‑control filters to identify and remove low‑quality synthetic data. Mixing real and synthetic data helps maintain diversity.
- Organizations should also invest in evaluation metrics that detect early signs of collapse, such as sudden uniformity in outputs or a decrease in the model’s ability to handle rare events.
Conclusion
Model collapse is a cautionary tale about the limits of self‑referential learning. As generative AI becomes more pervasive, developers and regulators must ensure that models stay grounded in real‑world information. Integrating authentic data and monitoring model behaviour are key to maintaining innovation and reliability.

