ಸುದ್ದಿಯಲ್ಲಿ ಏಕೆ?
ತಾಜಾ ಮಾನವ-ಉತ್ಪಾದಿತ ಡೇಟಾದ ಬದಲಿಗೆ generative AI ವ್ಯವಸ್ಥೆಗಳನ್ನು ತಮ್ಮದೇ ಆದ ಔಟ್ಪುಟ್ಗಳ ಮೇಲೆ ಪದೇ ಪದೇ ತರಬೇತಿ ನೀಡಿದಾಗ ಅವು “model collapse” (ಮಾದರಿ ಕುಸಿತ) ಗೆ ಒಳಗಾಗಬಹುದು ಎಂದು ಸಂಶೋಧಕರು ಎಚ್ಚರಿಸಿದ್ದಾರೆ. King’s College London, Norwegian University of Science and Technology (NTNU) ಮತ್ತು Abdus Salam International Centre for Theoretical Physics ನ ಹೊಸ ಅಧ್ಯಯನವು ತರಬೇತಿಗೆ ಕೇವಲ ಒಂದು ನೈಜ ಡೇಟಾ ಬಿಂದುವನ್ನು ಸೇರಿಸುವುದರಿಂದ ಈ ಅವನತಿಯನ್ನು ವಿಳಂಬಗೊಳಿಸಬಹುದು ಅಥವಾ ತಡೆಯಬಹುದು ಎಂದು ತೋರಿಸುತ್ತದೆ.
ಹಿನ್ನೆಲೆ
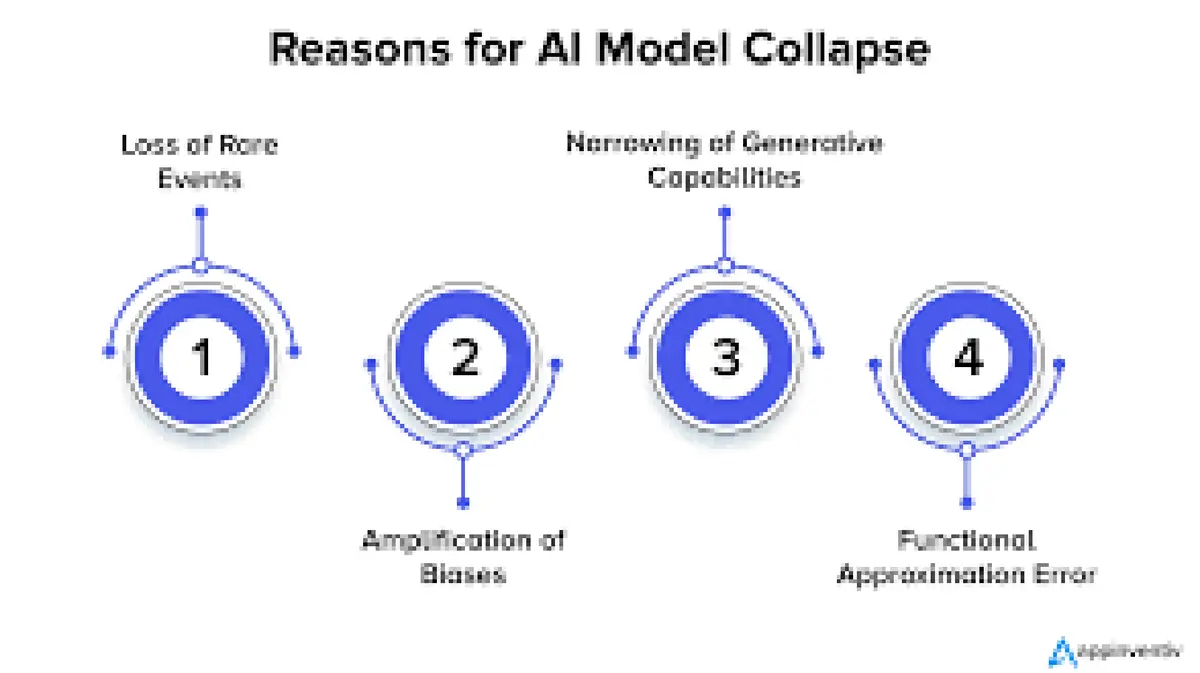
Generative AI ಮಾದರಿಗಳು—ದೊಡ್ಡ ಭಾಷಾ ಮಾದರಿಗಳು (large language models) ಅಥವಾ ಇಮೇಜ್ ಜನರೇಟರ್ಗಳು (image generators)—ಬೃಹತ್ ಡೇಟಾಸೆಟ್ಗಳಿಂದ ಮಾದರಿಗಳನ್ನು ಕಲಿಯುತ್ತವೆ ಮತ್ತು ನಂತರ ಹೊಸ ಪಠ್ಯ, ಚಿತ್ರಗಳು ಅಥವಾ ಸಂಗೀತವನ್ನು ರಚಿಸುತ್ತವೆ. ಭವಿಷ್ಯದ ಮಾದರಿಗಳನ್ನು ಹೆಚ್ಚಾಗಿ ಹಳೆಯ ಮಾದರಿಗಳು ಉತ್ಪಾದಿಸಿದ ವಿಷಯದ ಮೇಲೆ ತರಬೇತಿ ನೀಡಿದರೆ, ದೋಷಗಳು ಮತ್ತು ಪಕ್ಷಪಾತಗಳು (biases) ಸಂಗ್ರಹವಾಗಬಹುದು. ಅನುಕ್ರಮ ತಲೆಮಾರುಗಳಲ್ಲಿ (successive generations), ಮಾದರಿಗಳು ತಮ್ಮ ವೈವಿಧ್ಯತೆ ಮತ್ತು ವಾಸ್ತವಿಕ ನೆಲೆಯನ್ನು ಕಳೆದುಕೊಂಡು ಮಂದವಾದ (bland) ಅಥವಾ ಅಸಂಗತ ಔಟ್ಪುಟ್ಗಳ ಮೇಲೆ ಒಮ್ಮುಖವಾಗಬಹುದು (converge); ಈ ವಿದ್ಯಮಾನವನ್ನು model collapse ಎಂದು ಕರೆಯಲಾಗುತ್ತದೆ.
ಈ ಸಮಸ್ಯೆಯು “garbage in, garbage out” (ಕಸ ಒಳಗೆ, ಕಸ ಹೊರಗೆ) ಎಂದು ಕರೆಯಲ್ಪಡುವ ಹಳೆಯ ಪರಿಕಲ್ಪನೆಗೆ ಸಂಬಂಧಿಸಿದೆ: AI ಯ ಔಟ್ಪುಟ್ಗಳ ಗುಣಮಟ್ಟವು ಅದರ ತರಬೇತಿ ಡೇಟಾದ ಗುಣಮಟ್ಟವನ್ನು ಅವಲಂಬಿಸಿರುತ್ತದೆ. ಸಿಂಥೆಟಿಕ್ ಡೇಟಾವು ಪ್ರಾಬಲ್ಯ ಸಾಧಿಸಿದಾಗ, ಅಪರೂಪದ ವೈಶಿಷ್ಟ್ಯಗಳು ಮತ್ತು ಲಾಂಗ್-ಟೇಲ್ ಮಾಹಿತಿ (long‑tail information) ಕಣ್ಮರೆಯಾಗುತ್ತದೆ, ಇದು ಅಸಾಮಾನ್ಯ ಸಂದರ್ಭಗಳನ್ನು ಹೇಗೆ ನಿರ್ವಹಿಸುವುದು ಎಂಬುದನ್ನು ಮಾದರಿಯು ಮರೆತುಬಿಡುವಂತೆ ಮಾಡುತ್ತದೆ. ಪರಿಣಾಮವು ನರಮಂಡಲದ ಜಾಲಗಳಲ್ಲಿನ (neural networks) ವಿಪತ್ತಿನ ಮರೆವಿನೊಂದಿಗೆ (catastrophic forgetting) ಸಾಮ್ಯತೆಯನ್ನು ಹೊಂದಿದೆ.
ಇತ್ತೀಚಿನ ಸಂಶೋಧನೆಯ ಆವಿಷ್ಕಾರಗಳು
- ಅಧ್ಯಯನವು ಸಿಂಥೆಟಿಕ್ ಡೇಟಾದಲ್ಲಿ ಪುನರಾವರ್ತಿತ ಕಲಿಕೆಯನ್ನು ಅನುಕರಿಸಲು (simulate) ಘಾತೀಯ ಕುಟುಂಬಗಳು (exponential families) ಎಂಬ ಗಣಿತದ ಮಾದರಿಗಳನ್ನು ಬಳಸಿದೆ. ಡೇಟಾದ ವಿತರಣೆಯು ಕಾಲಾನಂತರದಲ್ಲಿ ಕಿರಿದಾಗುತ್ತದೆ ಎಂದು ಅದು ಕಂಡುಹಿಡಿದಿದೆ, ಇದರಿಂದಾಗಿ ಮಾದರಿಗಳು ಕುಗ್ಗುತ್ತಿರುವ ವೈವಿಧ್ಯಮಯ ಔಟ್ಪುಟ್ಗಳನ್ನು ಉತ್ಪಾದಿಸುತ್ತವೆ.
- ಕೇವಲ ಒಂದು ನೈಜ, ಔಟ್-ಆಫ್-ಡಿಸ್ಟ್ರಿಬ್ಯೂಷನ್ (out‑of‑distribution) ಡೇಟಾ ಪಾಯಿಂಟ್ ಅನ್ನು ಅಳವಡಿಸುವುದು ಅಥವಾ ತರಬೇತಿ ಪ್ರಕ್ರಿಯೆಯಲ್ಲಿ ಪೂರ್ವ ನಂಬಿಕೆಯನ್ನು (prior belief) ಎನ್ಕೋಡ್ ಮಾಡುವುದು ಈ ಕಿರಿದಾಗುವಿಕೆಗೆ ಅಡ್ಡಿಪಡಿಸುತ್ತದೆ ಮತ್ತು ಮಾದರಿಯ ಔಟ್ಪುಟ್ ಅನ್ನು ವಾಸ್ತವಕ್ಕೆ ಹತ್ತಿರವಾಗಿರಿಸುತ್ತದೆ.
- ಫಲಿತಾಂಶಗಳು ಹಲವಾರು ರೀತಿಯ ಉತ್ಪಾದಕ (generative) ಮಾದರಿಗಳಾದ್ಯಂತ ಅನ್ವಯಿಸುತ್ತವೆ, ಇದು ಸರಳವಾದ ಮಾರ್ಗಸೂಚಿಯನ್ನು ಸೂಚಿಸುತ್ತದೆ: ಯಾವಾಗಲೂ ನಿಜವಾದ ಮಾನವ ಡೇಟಾವನ್ನು ತರಬೇತಿ ಸೆಟ್ಗಳಲ್ಲಿ ಬೆರೆಸಿ ಮತ್ತು ಸಿಂಥೆಟಿಕ್ ವಿಷಯದ ಮೂಲವನ್ನು (provenance) ಟ್ರ್ಯಾಕ್ ಮಾಡಿ.
ಪರಿಣಾಮಗಳು ಮತ್ತು ತಗ್ಗಿಸುವಿಕೆ (Consequences and mitigation)
- ಪರಿಣಾಮಗಳು: Model collapse ವಿಶ್ವಾಸಾರ್ಹವಲ್ಲದ ಶಿಫಾರಸುಗಳು, ಕಳಪೆ ನಿರ್ಧಾರ-ತೆಗೆದುಕೊಳ್ಳುವಿಕೆ ಮತ್ತು ಸ್ವಯಂಚಾಲಿತ ವ್ಯವಸ್ಥೆಗಳಲ್ಲಿ ಜ್ಞಾನದ ಸವೆತಕ್ಕೆ ಕಾರಣವಾಗಬಹುದು. ಇದು ಬಳಕೆದಾರರ ನಂಬಿಕೆಯನ್ನು ದುರ್ಬಲಗೊಳಿಸುತ್ತದೆ ಮತ್ತು ವಿಷಯ ರಚನೆ, ವಿನ್ಯಾಸ ಅಥವಾ ರೋಗನಿರ್ಣಯಕ್ಕಾಗಿ (diagnostics) generative AI ಯನ್ನು ಅವಲಂಬಿಸಿರುವ ಕೈಗಾರಿಕೆಗಳಿಗೆ ಹಾನಿ ಮಾಡುತ್ತದೆ.
- ತಗ್ಗಿಸುವ ತಂತ್ರಗಳು: ಡೇಟಾ ಮೂಲಗಳನ್ನು ದಾಖಲಿಸಲು, ಮೂಲ ಡೇಟಾಸೆಟ್ಗಳ ಪ್ರವೇಶವನ್ನು ಸಂರಕ್ಷಿಸಲು ಮತ್ತು ಕಡಿಮೆ ಗುಣಮಟ್ಟದ ಸಿಂಥೆಟಿಕ್ ಡೇಟಾವನ್ನು ಗುರುತಿಸಲು ಮತ್ತು ತೆಗೆದುಹಾಕಲು ಗುಣಮಟ್ಟ-ನಿಯಂತ್ರಣ ಫಿಲ್ಟರ್ಗಳನ್ನು ಬಳಸಲು ಸಂಶೋಧಕರು ಶಿಫಾರಸು ಮಾಡುತ್ತಾರೆ. ನೈಜ ಮತ್ತು ಸಂಶ್ಲೇಷಿತ (synthetic) ಡೇಟಾವನ್ನು ಬೆರೆಸುವುದು ವೈವಿಧ್ಯತೆಯನ್ನು ಕಾಪಾಡಿಕೊಳ್ಳಲು ಸಹಾಯ ಮಾಡುತ್ತದೆ.
- ಔಟ್ಪುಟ್ಗಳಲ್ಲಿನ ಹಠಾತ್ ಏಕರೂಪತೆ (uniformity) ಅಥವಾ ಅಪರೂಪದ ಘಟನೆಗಳನ್ನು ನಿಭಾಯಿಸುವ ಮಾದರಿಯ ಸಾಮರ್ಥ್ಯದಲ್ಲಿನ ಇಳಿಕೆಯಂತಹ ಕುಸಿತದ ಆರಂಭಿಕ ಚಿಹ್ನೆಗಳನ್ನು ಪತ್ತೆಹಚ್ಚುವ ಮೌಲ್ಯಮಾಪನ ಮೆಟ್ರಿಕ್ಗಳಲ್ಲಿ ಸಂಸ್ಥೆಗಳು ಹೂಡಿಕೆ ಮಾಡಬೇಕು.
ತೀರ್ಮಾನ
Model collapse ಎಂಬುದು ಸ್ವಯಂ-ಉಲ್ಲೇಖಿತ ಕಲಿಕೆಯ (self‑referential learning) ಮಿತಿಗಳ ಕುರಿತಾದ ಎಚ್ಚರಿಕೆಯ ಕಥೆಯಾಗಿದೆ. Generative AI ಹೆಚ್ಚು ವ್ಯಾಪಕವಾಗುತ್ತಿದ್ದಂತೆ, ಡೆವಲಪರ್ಗಳು ಮತ್ತು ನಿಯಂತ್ರಕರು (regulators) ಮಾದರಿಗಳು ನೈಜ-ಪ್ರಪಂಚದ ಮಾಹಿತಿಯಲ್ಲಿ ನೆಲೆಗೊಂಡಿವೆ ಎಂದು ಖಚಿತಪಡಿಸಿಕೊಳ್ಳಬೇಕು. ಅಧಿಕೃತ ಡೇಟಾವನ್ನು ಸಂಯೋಜಿಸುವುದು ಮತ್ತು ಮಾದರಿಯ ನಡವಳಿಕೆಯನ್ನು ಮೇಲ್ವಿಚಾರಣೆ ಮಾಡುವುದು ನಾವೀನ್ಯತೆ ಮತ್ತು ವಿಶ್ವಾಸಾರ್ಹತೆಯನ್ನು ಕಾಪಾಡಿಕೊಳ್ಳುವ ಕೀಲಿಯಾಗಿದೆ.