వార్తల్లో ఎందుకు ఉంది?
మానవులు సృష్టించిన తాజా డేటాకు బదులుగా generative AI సిస్టమ్లకు వాటి స్వంత అవుట్పుట్లపై పదే పదే శిక్షణ ఇచ్చినప్పుడు అవి “model collapse” (మోడల్ పతనం) కి గురవుతాయని పరిశోధకులు హెచ్చరించారు. King’s College London, Norwegian University of Science and Technology (NTNU) మరియు Abdus Salam International Centre for Theoretical Physics ల కొత్త అధ్యయనం, శిక్షణలో కేవలం ఒక నిజమైన డేటా పాయింట్ను చేర్చడం వల్ల ఈ క్షీణతను ఆలస్యం చేయవచ్చు లేదా నిరోధించవచ్చు అని చూపిస్తుంది.
నేపథ్యం
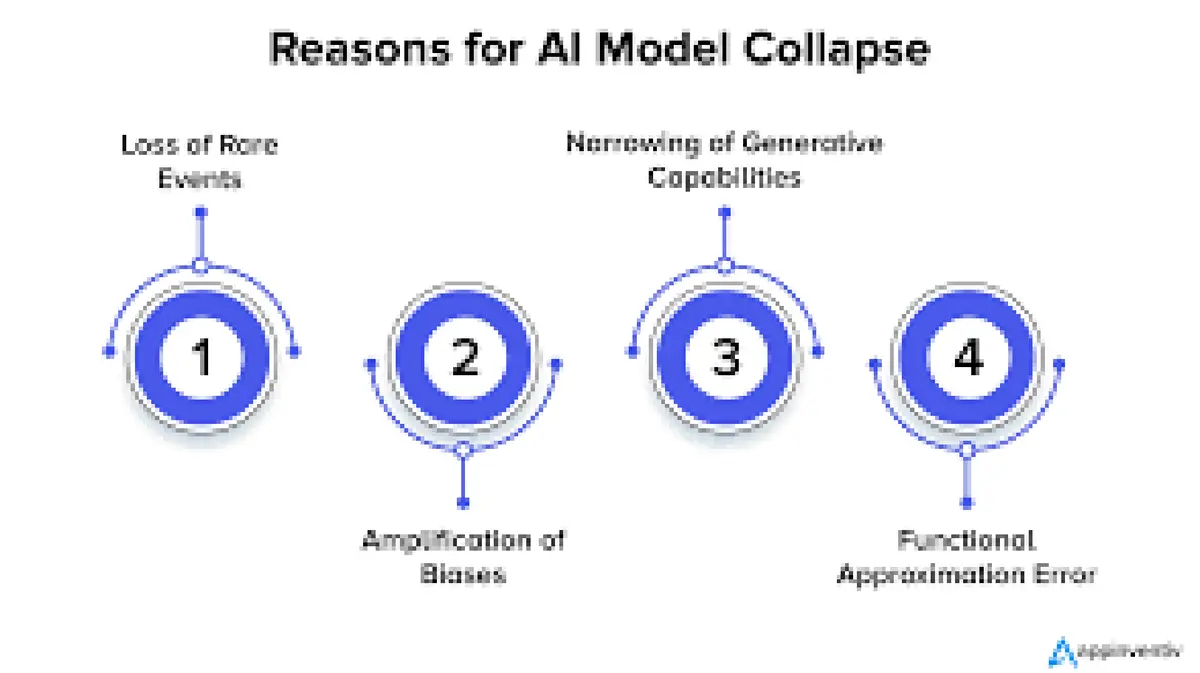
Generative AI నమూనాలు—పెద్ద భాషా నమూనాలు (large language models) లేదా ఇమేజ్ జనరేటర్లు (image generators)—పెద్ద డేటాసెట్ల నుండి నమూనాలను నేర్చుకుంటాయి మరియు తర్వాత కొత్త టెక్స్ట్, చిత్రాలు లేదా సంగీతాన్ని సృష్టిస్తాయి. భవిష్యత్తు నమూనాలు పాత నమూనాలు ఉత్పత్తి చేసిన కంటెంట్పై ఎక్కువగా శిక్షణ పొందితే, లోపాలు మరియు పక్షపాతాలు (biases) పేరుకుపోతాయి. వరుస తరాలలో (successive generations), నమూనాలు వాటి వైవిధ్యం మరియు వాస్తవికతను కోల్పోయి చప్పగా ఉండే (bland) లేదా అర్థరహిత అవుట్పుట్లపై కేంద్రీకృతమవుతాయి (converge); ఈ దృగ్విషయాన్ని model collapse అంటారు.
ఈ సమస్య “garbage in, garbage out” (గార్బేజ్ ఇన్, గార్బేజ్ అవుట్) అనే పాత భావనకు సంబంధించినది: AI అవుట్పుట్ల నాణ్యత దాని శిక్షణ డేటా నాణ్యతపై ఆధారపడి ఉంటుంది. సింథటిక్ డేటా ఆధిక్యత సాధించినప్పుడు, అరుదైన ఫీచర్లు మరియు సుదీర్ఘమైన సమాచారం (long‑tail information) అదృశ్యమవుతుంది, దీనివల్ల అసాధారణ పరిస్థితులను ఎలా ఎదుర్కోవాలో మోడల్ మర్చిపోతుంది. ఈ ప్రభావం న్యూరల్ నెట్వర్క్లలోని (neural networks) విపత్తు మతిమరుపుకు (catastrophic forgetting) సారూప్యంగా ఉంటుంది.
ఇటీవలి పరిశోధనలో కనుగొన్న విషయాలు
- సింథటిక్ డేటాపై పదే పదే నేర్చుకోవడాన్ని అనుకరించేందుకు (simulate) ఎక్స్పోనెన్షియల్ ఫ్యామిలీస్ (exponential families) అనే గణిత నమూనాలను అధ్యయనం ఉపయోగించింది. కాలక్రమేణా డేటా పంపిణీ తగ్గుతుందని, దీనివల్ల మోడల్లు కుదించుకుపోతున్న వైవిధ్యమైన అవుట్పుట్లను ఉత్పత్తి చేస్తాయని కనుగొన్నారు.
- ఒక నిజమైన, అవుట్-ఆఫ్-డిస్ట్రిబ్యూషన్ (out‑of‑distribution) డేటా పాయింట్ను చొప్పించడం లేదా శిక్షణా ప్రక్రియలో ముందస్తు నమ్మకాన్ని (prior belief) ఎన్కోడింగ్ చేయడం ఈ క్షీణతకు అంతరాయం కలిగిస్తుంది మరియు మోడల్ అవుట్పుట్ను వాస్తవికతకు దగ్గరగా ఉంచుతుంది.
- ఫలితాలు అనేక రకాల ఉత్పాదక (generative) నమూనాలకు వర్తిస్తాయి, ఇది ఒక సాధారణ మార్గదర్శకాన్ని సూచిస్తుంది: శిక్షణా సెట్లలో ఎల్లప్పుడూ నిజమైన మానవ డేటాను కలపండి మరియు సింథటిక్ కంటెంట్ యొక్క మూలాన్ని (provenance) ట్రాక్ చేయండి.
పరిణామాలు మరియు ఉపశమనం (Consequences and mitigation)
- పరిణామాలు: Model collapse విశ్వసించదగని సిఫార్సులు, పేలవమైన నిర్ణయం తీసుకోవడం మరియు ఆటోమేటెడ్ సిస్టమ్స్లో (automated systems) జ్ఞానం కోల్పోవడానికి దారితీస్తుంది. ఇది వినియోగదారుల నమ్మకాన్ని దెబ్బతీస్తుంది మరియు కంటెంట్ సృష్టి, డిజైన్ లేదా రోగ నిర్ధారణ (diagnostics) కోసం generative AI పై ఆధారపడే పరిశ్రమలకు హాని కలిగిస్తుంది.
- ఉపశమన వ్యూహాలు (Mitigation strategies): డేటా మూలాలను డాక్యుమెంట్ చేయడానికి, అసలు డేటాసెట్ల యాక్సెస్ను సంరక్షించడానికి మరియు తక్కువ నాణ్యత గల సింథటిక్ డేటాను గుర్తించి తొలగించడానికి నాణ్యత-నియంత్రణ ఫిల్టర్లను (quality‑control filters) ఉపయోగించాలని పరిశోధకులు సిఫార్సు చేస్తున్నారు. నిజమైన మరియు సింథటిక్ (synthetic) డేటాను కలపడం వైవిధ్యాన్ని కాపాడుకోవడానికి సహాయపడుతుంది.
- అవుట్పుట్లలో అకస్మాత్తుగా ఏకరూపత (uniformity) లేదా అరుదైన సంఘటనలను నిర్వహించే మోడల్ సామర్థ్యం తగ్గడం వంటి పతనం యొక్క ప్రారంభ సంకేతాలను గుర్తించే మూల్యాంకన కొలమానాలలో (evaluation metrics) సంస్థలు పెట్టుబడి పెట్టాలి.
ముగింపు
Model collapse అనేది స్వీయ-సూచన అభ్యాసం (self‑referential learning) యొక్క పరిమితుల గురించిన ఒక హెచ్చరిక కథ. Generative AI మరింత ప్రబలంగా మారుతున్నందున, డెవలపర్లు మరియు రెగ్యులేటర్లు (regulators) నమూనాలు వాస్తవ ప్రపంచ సమాచారంతో కూడి ఉన్నాయని నిర్ధారించుకోవాలి. ప్రామాణికమైన డేటాను చేర్చడం మరియు మోడల్ ప్రవర్తనను పర్యవేక్షించడం అనేది ఆవిష్కరణ మరియు విశ్వసనీయతను నిర్వహించడానికి కీలకం.